BERT Word Embeddings Deep Dive
Dives into BERT word embeddings with step by step implementation details using PyTorch
In 2018, the Google AI team made a revolutionary change in the field of Natural Language Processing ( NLP) by introducing Bidirectional Encoder Representations from Transformers (BERT). Due to its highly pragmatic approach, and higher performance, BERT is highlighted for achieving state-of-the-art performance in many NLP tasks
In this blog, we’ll be looking at word embeddings and see how BERT can be used with word-embedding strategies to feed as input features for other models built for custom tasks to perform the state of art results. This blog includes all the information I gathered while researching the word embedding task for my final year project.
Word Embedding
“Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers.”
What are word embeddings exactly? Simply, they are vector representations of a particular word. Word embedding is one of the most popular representations of document vocabulary. It is capable of capturing the context of a word in a document, semantic and syntactic similarity, relation with other words, etc. Word embeddings are mostly used as input features for other models built for custom tasks.
There are a few key characteristics to a set of useful word embeddings:
- Every word has a unique word embedding (or “vector”), which is just a list of numbers for each word.
- The word embeddings are multidimensional; typically for a good model, embeddings are between 50 and 500 in length.
- For each word, the embedding captures the “meaning” of the word.
- Similar words end up with similar embedding values.
There are many approaches to generate word embeddings. Context-independent (Bag of Words, TF-IDF, Word2Vec, GloVe), Context-aware (ELMo, Transformer, BERT, Transformer-XL), Large model (GPT-2, XLNet, Compressive Transformer) are the main categories. If you want to go deep into these approaches, please refer to this blog.
Why BERT Embedding?
BERT has an advantage over models like Word2Vec because while each word has a fixed representation under Word2Vec regardless of the context within which the word appears, BERT produces word representations that are dynamically informed by the words around them. For example, given two sentences:
“The man was accused of robbing a bank.”
“The man went fishing by the bank of the river.”
In both sentences, Word2Vec would create the same word embedding for the word “bank,” while under BERT the word embedding for “bank” would vary for each sentence. Aside from capturing obvious differences like polysemy, the context-informed word embeddings capture other forms of information that result in more accurate feature representations, which in turn results in better model performance.
BERT Model
Before we move into the code, let’s just quickly explore the architecture of BERT so that at implementation time we have a bit of context. Believe me, it’ll make it a lot easier to understand things.
Two primary models were created by BERT developers:
- The BASE: Number of transformer blocks (L): 12, Hidden layer size (H): 768 and Attention heads(A): 12
- The LARGE: Number of transformer blocks (L): 24, Hidden layer size (H): 1024 and Attention heads(A): 16
From a very high-level perspective, BERT’s architecture(BASE model) looks like this:
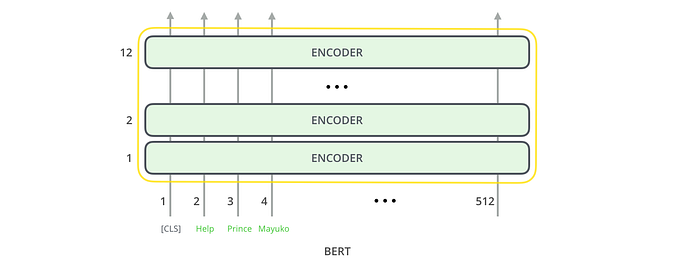
It may seem simple but remember that each encoder block encapsulates a more sophisticated model architecture.
Input Formatting
BERT expects input data in a specific format, with special tokens to mark the beginning ([CLS]) and separation/end of sentences ([SEP]). Furthermore, we need to tokenize our text into tokens that correspond to BERT’s vocabulary. For each tokenized sentence, BERT requires input ids, a sequence of integers identifying each input token to its index number in the BERT tokenizer vocabulary.

Understanding Output
Depending on the configuration (BertConfig) and inputs, BertModel returns the following outputs;
- last_hidden_state — Sequence of hidden-states at the output of the last layer of the model.
- pooler_output — Last layer hidden-state of the first token of the sequence
- hidden_states (optional, returned when
output_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) – Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (optional, returned when
output_attentions=Trueis passed or whenconfig.output_attentions=True) – Attention weights after the attention softmax used to compute the weighted average in the self-attention heads.
An explanation into hidden_states
The full set of hidden states of the model, stored in the object hidden_states, is a little dizzying. This object has four dimensions, in the following order:
- The layer number (13 layers)
- The batch number (num of sentences)
- The word/token number (maximum length of sentences)
- The hidden unit/feature number (768 features)
Wait, 13 layers? Doesn’t BERT only have 12? It’s 13 because the first element is the input embeddings, the rest is the outputs of each of BERT’s 12 layers.
Word Embedding with BERT Model
It’s all wonderful so far, but how do I get word embeddings from this? The BERT base model uses 12 layers of transformer encoders as discussed, and each output per token from each layer of these can be used as a word embedding!. Perhaps you wonder which is the best, though?
By feeding various vector combinations as input features to a BiLSTM used on a named entity recognition task and observing the resulting F1 ratings, the BERT authors checked word-embedding strategies. The authors identified that one of the best performing choices was to sum the last 4 layers.
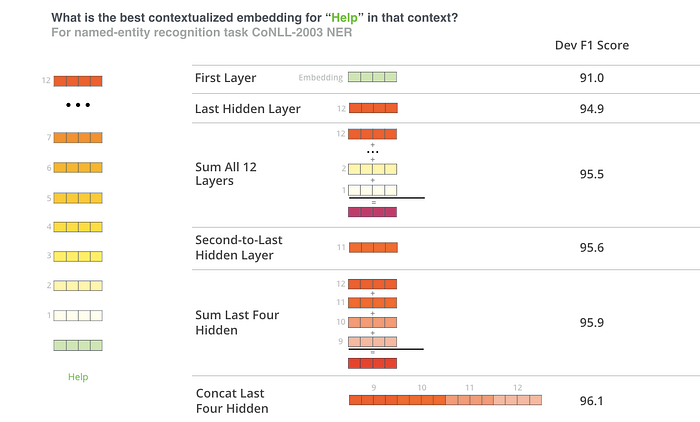
Step by step implementation
Enough with the theory. Let’s move on to the practice and see how the above word-embedding strategies are used in PyTorch code implementation.
In this section, we’ll highlight the code to extract the word embedding from the BERT model. A notebook containing all this code is available on colab.
Let’s start by importing the tools of the trade. The two modules imported from BERT are modeling and tokenization. Modeling includes the BERT model (BASE model) implementation and tokenization is obviously for tokenizing the input text.
import torch
from pytorch_transformers import BertTokenizer
from pytorch_transformers import BertModel## Load pretrained model/tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertModel.from_pretrained('bert-base uncased',output_hidden_states=True)
Convert the input data into the required format for the BERT model using the tokenizer.
# Define an input text
text = "Here is the sentence I want embeddings for."# Add the special tokens.
marked_text = "[CLS] " + text + " [SEP]"# Split the sentence into tokens.
tokenized_text = tokenizer.tokenize(marked_text)# Map the token strings to their vocabulary indeces.
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)# Display the words with their indeces.
for tup in zip(tokenized_text, indexed_tokens):
print('{:<12} {:>6,}'.format(tup[0], tup[1]))
Convert the input into torch tensors and call the BERT model.
import torch# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])# Put the model in "evaluation" mode,meaning feed-forward operation.
model.eval()
Running BERT on the input and extract the word embedding in different ways using the model output.
#Run the text through BERT, get the output and collect all of the hidden states produced from all 12 layers.with torch.no_grad():
outputs = model(tokens_tensor)# can use last hidden state as word embeddings
last_hidden_state = outputs[0]
word_embed_1 = last_hidden_state# Evaluating the model will return a different number of objects based on how it's configured in the `from_pretrained` call earlier. In this case, becase we set `output_hidden_states = True`, the third item will be the hidden states from all layers. See the documentation for more details:https://huggingface.co/transformers/model_doc/bert.html#bertmodelhidden_states = outputs[2]# initial embeddings can be taken from 0th layer of hidden states
word_embed_2 = hidden_states[0]# sum of all hidden states
word_embed_3 = torch.stack(hidden_states).sum(0)# sum of second to last layer
word_embed_4 = torch.stack(hidden_states[2:]).sum(0)# sum of last four layer
word_embed_5 = torch.stack(hidden_states[-4:]).sum(0)# concatenate last four layers
word_embed_6 = torch.cat([hidden_states[i] for i in [-1,-2,-3,-4]], dim=-1)
The word embedding by concatenating the last four layers(word_emb_6), giving us a single word vector per token. Each vector will have a length 4 x 768 = 3,072. All other word embeddings have the 768 length vectors per token. You can use any of these ways to get word embedding as input features for other models built for custom tasks according to the model performance.
I hope you enjoyed the blog and hopefully got a clearer picture of BERT embedding. In the comments section, feel free to post your feedback.
References:
[1] https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/
[2]”BERT — transformers 3.3.0 documentation”, Huggingface.co
[4]https://medium.com/@dhartidhami/understanding-bert-word-embeddings-7dc4d2ea54ca.
[5]J. Alammar, “A Visual Guide to Using BERT for the First Time”, Jalammar.github.io
[6] “Get Busy with Word Embeddings — An Introduction”, Shane Lynn
